How to predict missing data
LinkML implements the “CRUDSI” design pattern. In addition to Create, Read, Update, Delete, LinkML also supports Search and Inference.
The framework is designed to support different kinds of inference, including rule-based and LLMs. This notebooks shows simple ML-based inference using scikit-learn DecisionTrees.
This how-to walks through the basic operations of using the linkml-store command line tool to perform training and inference using scikit-learn DecisionTrees. This uses the command line interface, but the same operations can be performed programmatically using the Python API, or via the Web API.
We will use a subset of the classic Iris dataset, converted to jsonl (JSON Lines) format:
[2]:
%%bash
linkml-store -i ../../tests/input/iris.jsonl describe
count unique top freq mean std min 25% 50% 75% max
petal_length 100.0 NaN NaN NaN 2.861 1.449549 1.0 1.5 2.45 4.325 5.1
petal_width 100.0 NaN NaN NaN 0.786 0.565153 0.1 0.2 0.8 1.3 1.8
sepal_length 100.0 NaN NaN NaN 5.471 0.641698 4.3 5.0 5.4 5.9 7.0
sepal_width 100.0 NaN NaN NaN 3.099 0.478739 2.0 2.8 3.05 3.4 4.4
species 100 2 setosa 50 NaN NaN NaN NaN NaN NaN NaN
The Infer Command
[5]:
%%bash
linkml-store infer --help
Usage: linkml-store infer [OPTIONS]
Predict a complete object from a partial object.
Currently two main prediction methods are provided: RAG and sklearn
## RAG:
The RAG approach will use Retrieval Augmented Generation to inference the
missing attributes of an object.
Example:
linkml-store -i countries.jsonl inference -t rag -q 'name: Uruguay'
Result:
capital: Montevideo, code: UY, continent: South America, languages:
[Spanish]
You can pass in configurations as follows:
linkml-store -i countries.jsonl inference -t
rag:llm_config.model_name=llama-3 -q 'name: Uruguay'
## SKLearn:
This uses scikit-learn (defaulting to simple decision trees) to do the
prediction.
linkml-store -i tests/input/iris.csv inference -t sklearn -q
'{"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4,
"petal_width": 0.2}'
Options:
-O, --output-type [json|jsonl|yaml|yamll|tsv|csv|python|parquet|formatted|table|duckdb|postgres|mongodb]
Output format
-o, --output PATH Output file path
-T, --target-attribute TEXT Target attributes for inference
-F, --feature-attributes TEXT Feature attributes for inference (comma
separated)
-Y, --inference-config-file PATH
Path to inference configuration file
-E, --export-model PATH Export model to file
-L, --load-model PATH Load model from file
-M, --model-format [pickle|onnx|pmml|pfa|joblib|png|linkml_expression|rulebased|rag_index]
Format for model
-S, --training-test-data-split <FLOAT FLOAT>...
Training/test data split
-t, --predictor-type TEXT Type of predictor [default: sklearn]
-n, --evaluation-count INTEGER Number of examples to evaluate over
--evaluation-match-function TEXT
Name of function to use for matching objects
in eval
-q, --query TEXT query term
--help Show this message and exit.
Training and Inference
We can perform training and inference in a single step.
For feature labels, we use:
petal_lengthpetal_widthsepal_lengthsepal_width
These can be explicitly specified using -F, but in this case we are specifying a query, so the feature labels are inferred from the query.
We specify the target label using -T. In this case, we are predicting the species of the iris.
[4]:
%%bash
linkml-store -i ../../tests/input/iris.jsonl infer -t sklearn -T species -q "{petal_length: 2.5, petal_width: 0.5, sepal_length: 5.0, sepal_width: 3.5}"
/Users/cjm/Library/Caches/pypoetry/virtualenvs/linkml-store-8ZYO4kTy-py3.10/lib/python3.10/site-packages/sklearn/base.py:493: UserWarning: X does not have valid feature names, but DecisionTreeClassifier was fitted with feature names
warnings.warn(
predicted_object:
species: setosa
confidence: 1.0
The data model for the output consists of a predicted_object slot and a confidence. Note that for standard ML operations, the predicted object will typically have one attribute only, but other kinds of inference (OWL reasoning, LLMs) may be able to predict complex objects.
Saving the Model
Performing training and inference in a single step is convenient where training is fast, but more typically we’d want to save the model for later use.
We can do this with the -E option:
[11]:
%%bash
linkml-store -i ../../tests/input/iris.jsonl infer -t sklearn -T species -E "tmp/iris-model.joblib"
We can use a pre-saved model in inference:
[14]:
%%bash
linkml-store -i ../../tests/input/iris.jsonl infer -t sklearn -L "tmp/iris-model.joblib" -q "{petal_length: 2.5, petal_width: 0.5, sepal_length: 5.0, sepal_width: 3.5}"
/Users/cjm/Library/Caches/pypoetry/virtualenvs/linkml-store-8ZYO4kTy-py3.10/lib/python3.10/site-packages/sklearn/base.py:493: UserWarning: X does not have valid feature names, but DecisionTreeClassifier was fitted with feature names
warnings.warn(
predicted_object:
species: setosa
confidence: 1.0
Exporting models to explainable visualizations
We can export the model to a visual representation to make it more explaininable:
[9]:
%%bash
linkml-store --stacktrace -i ../../tests/input/iris.jsonl infer -t sklearn -T species -L tmp/iris-model.joblib -E input/iris-model.png
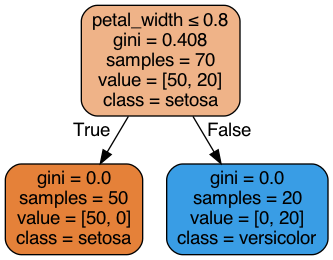
Generating a rule-based model
Although traditionally ML is used for statistical inference, sometimes we might want to use ML (e.g. Decision Trees) to generate simple purely deterministic rule-based models.
linkml-store has a different kind of inference engine that works using LinkML schemas, specifically
rulesat the class an slot levelexpressionsthat combine slot assignments logically and artithmetically
We can export (some) ML models to this format:
[10]:
%%bash
linkml-store -i ../../tests/input/iris.jsonl infer -t sklearn -T species -L tmp/iris-model.joblib -E tmp/iris-model.rulebased.yaml
cat tmp/iris-model.rulebased.yaml
class_rules: null
config:
feature_attributes:
- petal_length
- petal_width
- sepal_length
- sepal_width
target_attributes:
- species
slot_expressions:
species: ("setosa" if ({petal_width} <= 0.8000) else "versicolor")
slot_rules: null
We can then apply this model to new data:
[32]:
%%bash
linkml-store --stacktrace -i ../../tests/input/iris.jsonl infer -t rulebased -L tmp/iris-model.rulebased.yaml -q "{petal_length: 2.5, petal_width: 0.5, sepal_length: 5.0, sepal_width: 3.5}"
EVAL {'petal_length': 2.5, 'petal_width': 0.5, 'sepal_length': 5.0, 'sepal_width': 3.5}
predicted_object:
petal_length: 2.5
petal_width: 0.5
sepal_length: 5.0
sepal_width: 3.5
species: setosa
More advanced ML models
Currently only Decision Trees are supported. Additionally, most of the underlying functionality of scikit-learn is hidden.
For more advanced ML, you are encouraged to use linkml-store for data management and then exporting to standard tabular ot dataframe formats in order to do more advanced ML in Python. linkml-store is not intended as an ML platform. Instead a limited set of operations are provided to assist with data exploration and assisting in construction of deterministic rules.
For inference using LLMs and Retrieval Augmented Generation, see the how-to guide on those topics.
[ ]: